

In the world of programming, handling data efficiently is crucial. Whether you're building a search engine, managing databases, or developing an AI model, the way you store, organize, and manipulate data affects performance and scalability.
This is where understanding what is data structures come in! Understanding what are linear data structures helps in choosing the right approach for storing and processing data efficiently in programming.
What is Data Structure?
What are data structures in Python? They are specialized formats like lists, tuples, dictionaries, and trees that help store, organize, and manage data efficiently.A data structure is a way of organizing, managing, and storing data efficiently so that it can be used effectively.
Imagine a bookshelf:
- You can keep books randomly (hard to find a book).
- You can organize them alphabetically (easier to find).
- You can have different shelves for different genres (efficient categorization).
Data structures help us organize data properly so that we can access, modify, and store it efficiently.
A data structure is a systematic way of organizing and storing data so that it can be accessed and modified efficiently. The choice of a data structure affects the efficiency of operations like searching, sorting, and inserting data.
Also Read: What is Tuple in Python: A Beginner’s Guide to Tuples in Python
Why Do We Need Data Structures?
- Efficient Data Management – Helps organize and process large amounts of data effectively.
- Optimized Searching & Sorting – Improves algorithm performance.
- Better Memory Utilization – Reduces unnecessary memory usage.
- Scalability – Ensures efficient handling of large datasets.
- Faster Execution of Programs – Reduces computational time.
Understanding what are data structures in Python is essential for writing optimized code and solving complex problems in programming.
Now, let's dive deeper into the types of data structures.
Types of Data Structures
Data structures are broadly classified into two types:
- Linear Data Structures (Ordered Data):
They store data sequentially, meaning elements are arranged in a specific order where each element is connected to its previous and next element. Examples include arrays, linked lists, stacks, and queues. These structures are easy to implement and provide efficient traversal methods, but they may have limitations in terms of flexibility and speed for certain operations. For instance, arrays allow O(1) access time, but inserting or deleting elements requires shifting, making it O(N). Stacks and queues follow specific order rules (LIFO and FIFO) and are commonly used in function calls, undo operations, and task scheduling.
Examples include:
- Array
- Linked List
- Stack
- Queue
- Non-Linear Data Structures (Hierarchical Data):
They do not follow a sequential order, allowing data to be connected in multiple ways. Examples include trees, graphs, and hash tables, which are used for hierarchical, interconnected, or quick lookup-based applications. Trees, such as binary search trees (BST), allow fast searching and sorting operations, often in O(log N) time, while graphs are essential for modeling relationships in networks like social media and road maps. Hash tables provide nearly O(1) lookup time, making them ideal for databases and caching. While nonlinear structures offer more flexibility and efficiency in complex scenarios, they require more advanced implementation and memory management.Examples include:
- Trees
- Graphs
- Hash Tables
- Heaps
Let’s dive deeper into each data structure, covering their concepts, operations, advantages, disadvantages, and real-world uses.
Arrays
An array is a collection of fixed-size elements stored in contiguous memory locations. It allows direct access to any element using its index.

How It Works
- Arrays have a fixed size (in static arrays) set at creation.
- Elements are stored sequentially, making access fast.
- Each element can be accessed using an index starting from 0.

Advantages
- Easy access – Direct access to elements using an index.
- Memory efficiency – Uses contiguous memory, reducing overhead.
- Simplifies coding – Useful in sorting, searching, and storing bulk data.
Disadvantages
- Fixed size – Cannot dynamically grow or shrink (in static arrays).
- Insertion & deletion are slow – Since elements must be shifted.
- Wasted space – If an array is too large, unused space is wasted.
Real-World Use Cases
- Game development – Storing player scores, object positions.
- Databases – Storing fixed-size records.
- Computer graphics – Representing images as pixel arrays.
Also Read: Difference Between List and Tuple in Python: Key Differences Explained
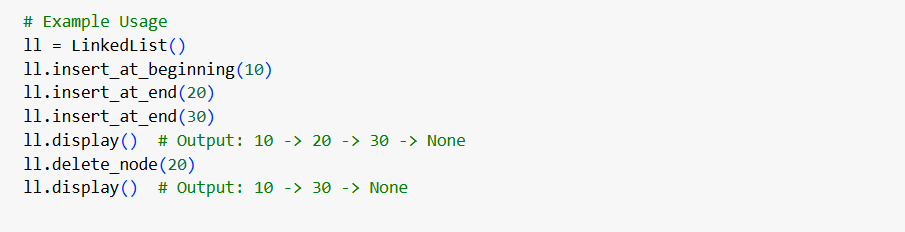
Linked Lists
A linked list is a collection of nodes where each node contains data and a pointer to the next node. Unlike arrays, linked lists are not stored in contiguous memory locations.
Types of Linked Lists
- Singly Linked List – Each node points to the next node.
- Doubly Linked List – Each node points to both next and previous nodes.
- Circular Linked List – The last node connects to the first node.
How It Works
- A linked list starts with a head node.
- Each node contains data and a link to the next node (or previous, in DLL).
- To traverse a linked list, you must follow the pointers from node to node.
Advantages
- Dynamic size – Can grow or shrink as needed.
- Efficient insertions/deletions – No need for shifting elements.
- No memory wastage – Unlike arrays, it doesn’t require pre-allocated space.
Disadvantages
- Slower access – Cannot directly access an element (must traverse nodes).
- Extra memory usage – Requires storage for pointers along with data.
- Complex implementation – Requires careful pointer management.
Real-World Use Cases
- Music playlists – Songs are linked in order.
- Undo/Redo feature – Stores previous states of a document.
- Memory allocation – Used by OS to manage free memory.
Stacks
A stack is a data structure that follows the LIFO (Last In, First Out) principle. This means that the last element added is the first to be removed.
How It Works
- Uses two main operations:
- Push – Adds an element to the top of the stack.
- Pop – Removes the top element from the stack.
- A stack can be implemented using arrays or linked lists.

Advantages
- Simple operations – Only push and pop required.
- Efficient memory usage – No need for extra space if implemented using an array.
- Easy to implement – Can be implemented using basic lists or arrays.
Disadvantages
- Limited access – Only the top element can be accessed.
- Overflow/Underflow risk – If the stack is full or empty, operations fail.
Real-World Use Cases
- Function calls in programming – Call stack maintains active function calls.
- Undo/Redo in text editors – Stores past actions for reversal.
- Backtracking algorithms – Used in solving mazes and recursion.
Also Read: Top 10 Features of Python Programming Language You Should Know
Queues
A queue follows the FIFO (First In, First Out) principle. This means that the first element added is the first to be removed.
Types of Queues
- Simple Queue – Elements enter from the rear and leave from the front.
- Circular Queue – The last position connects to the first, forming a loop.
- Priority Queue – Elements are removed based on priority, not order.
- Deque (Double-ended Queue) – Insert and remove elements from both ends.
How It Works
- Uses two main operations:
- Enqueue – Adds an element at the rear.
- Dequeue – Removes an element from the front.
- Can be implemented using arrays or linked lists.

Advantages
- Efficient processing of tasks – Tasks are handled in order.
- Ensures fairness – First-come, first-served order maintained.
Disadvantages
- Limited access – Only front and rear elements can be accessed.
Real-World Use Cases
- Printer queue – Tasks are printed in order.
- Call center – Customers served in order.
- Task scheduling in OS – Manages background processes.
Trees
A tree is a hierarchical data structure where each node has a parent-child relationship.
Types of Trees
- Binary Tree – Each node has at most two children.
- Binary Search Tree (BST) – A sorted tree where left child < root < right child.
- AVL Tree – A self-balancing BST.
- Trie – A special tree for fast text searching.
How It Works
- A tree starts from a root node.
- Each node can have multiple children.
- Traversal can be preorder, inorder, or postorder.

Advantages
- Fast search & insertion
- Hierarchical storage structure
Disadvantages
- Complex implementation
- Requires extra memory
Real-World Use Cases
- File system directories – Folders inside folders.
- AI decision-making – Decision trees in ML.
Database indexing – B-Trees in databases.
Graphs
A graph is a collection of nodes (vertices) and edges that connect them.
Types of Graphs
- Directed Graph – Edges have directions (A → B).
- Undirected Graph – Edges have no direction (A – B).
- Weighted Graph – Edges have weights (costs).
How It Works
- Nodes are connected using edges.
- A graph can be represented using adjacency lists or matrices.
Advantages
- Models complex relationships easily
- Efficient for networking problems
Disadvantages
- Difficult to implement
- Consumes more memory
Real-World Use Cases
- Google Maps – Finds the shortest path between locations.
- Social networks – Represents friendships or followers.
- Recommendation systems – Netflix uses graphs for suggestions.
Also Read: How to Load and Manipulate Datasets in Python Using Pandas
Hash Tables (Hash Maps)
A hash table (or hash map) is a data structure that stores key-value pairs. It uses a hash function to compute an index (or hash code) for storing values in an array.
How It Works
- A key is passed through a hash function to generate an index.
- The value is stored at the computed index.
- If multiple keys hash to the same index, a collision occurs, handled using:
- Chaining – Store multiple values in a linked list at the same index.
- Open addressing – Find another empty slot nearby.

Advantages
Fast access – Direct key-based lookup.
Efficient insertion & deletion – Works in constant time on average.
Disadvantages
Collisions can degrade performance
Requires good hash functions
Real-World Use Cases
Databases – Used for indexing records efficiently.
Dictionaries in Python – Key-value storage.
Caching systems – Web browsers store frequently accessed data in a cache.
Heaps
A heap is a special tree-based data structure where the parent node has a priority relationship with its children.
Types of Heaps
- Min Heap – The parent node is smaller than its children (smallest element is at the root).
- Max Heap – The parent node is greater than its children (largest element is at the root).
How It Works
- A heap is usually implemented as a binary tree stored in an array.
- The smallest (or largest) element is always at the root.
- The heap is modified using insertion, deletion, and heapify operations.

Advantages
- Efficient priority-based access – Fast retrieval of max/min values.
- Memory-efficient – Uses an array for storage.
Disadvantages
- Not ideal for searching – Linear traversal needed.
- Tree balancing required – Needs reordering when modified.
Real-World Use Cases
- Priority Queues – Used in scheduling tasks.
- Heap Sort Algorithm – Sorting large datasets efficiently.
- Dijkstra’s Algorithm – Used in shortest path problems.
Conclusion
In this guide, we explored what a data structure is, its types, and its importance in organizing and managing data efficiently. We also answered what are linear data structures, explaining how elements are arranged sequentially in arrays, linked lists, stacks, and queues. Additionally, we discussed what are data structures in Python, covering lists, tuples, dictionaries, and trees that help optimize data handling. Mastering these concepts is essential for writing efficient algorithms and solving complex programming challenges.



.avif)






.avif)
