

Convolutional Neural Networks (CNNs) are one of the most powerful and widely used types of neural networks, especially for tasks involving visual data such as image classification, object detection, and video analysis. They have revolutionized the field of computer vision and are essential for anyone working with image-based machine learning tasks. If you're new to machine learning or deep learning, building your first CNN can be a fantastic way to get hands-on experience with this transformative technology. In this guide, we will walk you through the process of building a simple CNN using Python and TensorFlow, while answering the fundamental question: What are convolutional neural networks?
What is Convolutional Neural Networks (CNNs)?
A convolutional neural network is a specialized type of deep neural network used primarily for processing structured grid data, such as images. CNNs are designed to automatically and adaptively learn spatial hierarchies of features from input images, making them highly efficient for tasks like image recognition and object detection. The key innovation of CNNs is the use of convolutional layers that apply convolution operations to extract important features from the input data.
The most common use of CNNs is in image-related tasks, where the network learns to identify patterns like edges, textures, and more complex shapes. Convolutional networks have become the go-to architecture for deep convolutional neural networks (DCNNs), which are simply deeper versions of CNNs with more layers for enhanced feature extraction. This makes them ideal for handling more complex tasks, like classifying thousands of different objects in large datasets.
Key Components of a Convolutional Neural Network
Convolutional Neural Networks (CNNs) are designed to work with grid-like data structures, such as images, which makes them incredibly powerful for tasks like image classification, object detection, and more. The architecture of a CNN is typically composed of several different types of layers, each of which performs a specific function to help the model learn and extract meaningful features from the input data. Here are the key components of a convolutional neural network:
1. Convolutional Layers
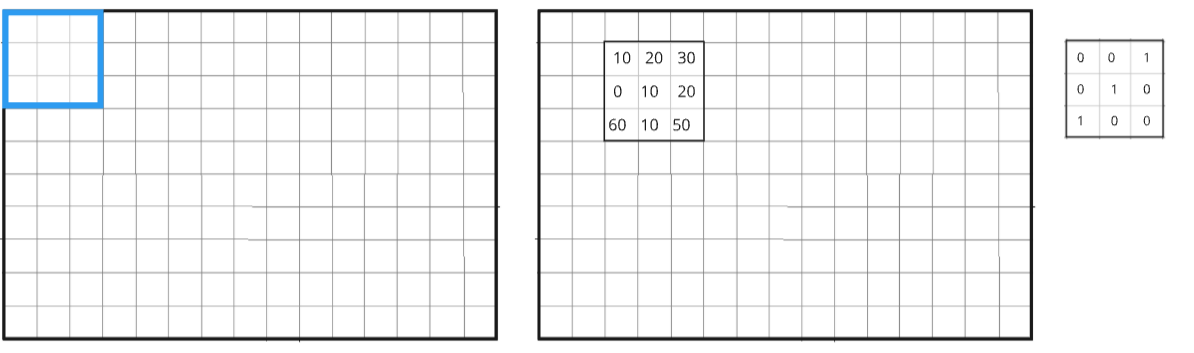
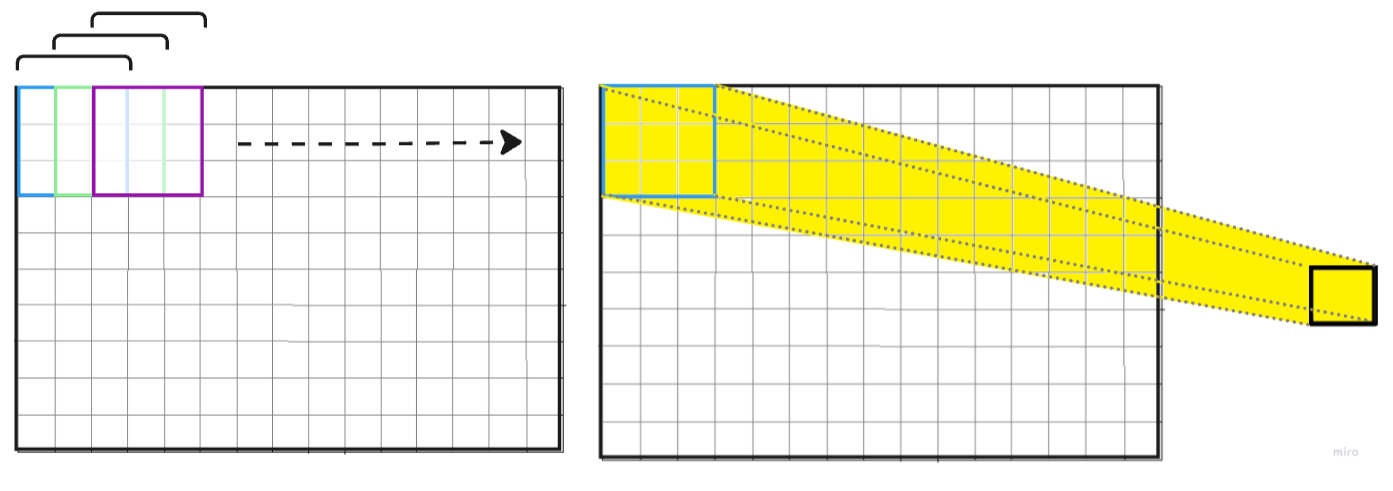
The convolutional layer is the core building block of a CNN and is primarily responsible for feature extraction. It works by applying a set of filters (also known as kernels) across the input image in a sliding window fashion, performing a mathematical operation known as convolution.
- Filters/Kernels: Filters are small weight matrices that scan through the image. Each filter detects a specific feature like edges, textures, or color gradients in the image. These filters are learned during the training process.
- Convolution Operation: The filter slides over the input image, multiplying corresponding pixel values and summing them to produce a feature map. This helps highlight important features in the image, such as edges, curves, and textures.
- Feature Maps: The result of the convolution operation is a feature map. It contains the learned features (edges, corners, etc.) at different spatial positions in the image.
- Example: If the network is tasked with recognizing faces, the filters might detect specific facial features such as eyes, nose, or lips.
2. Activation Function (ReLU)
After a convolution operation, the feature map often passes through an activation function, typically the ReLU (Rectified Linear Unit) activation function in CNNs. The purpose of the activation function is to introduce non-linearity into the network, enabling it to learn complex patterns in the data.
- ReLU: The ReLU activation function replaces all negative values in the feature map with zero and keeps positive values as they are. Mathematically, it's defined as:
f(x)=max(0,x)f(x) = \max(0, x) - Why ReLU: ReLU is widely used in CNNs because it speeds up training by reducing the likelihood of vanishing gradients (a problem seen in other activation functions like sigmoid or tanh). ReLU also helps the network learn sparse features, making it computationally efficient.
- Example: If a convolutional layer detects edges in an image, the ReLU activation will zero out irrelevant parts of the image and highlight important edges, making the subsequent layers focus on the critical features.
3. Pooling Layers (Max Pooling)
The pooling layer is used to reduce the spatial dimensions (height and width) of the feature maps while retaining the most critical information. This process, called downsampling, helps reduce computational complexity and prevents overfitting by removing unnecessary details.
- Max Pooling: The most common pooling operation in CNNs is max pooling. In this operation, a small window (usually 2x2 or 3x3) slides over the feature map, and for each region of the feature map, it selects the maximum value. This helps retain the most important features while reducing the size of the feature map.
- Why Pooling? Pooling makes the model more invariant to small changes in the position of features. For example, whether an edge is slightly shifted or rotated, the network can still recognize it.
- Example: In face detection, if the network detects an eye in the image, max pooling helps retain the key information about the eye’s position while ignoring irrelevant features like minor variations in the eye's texture or size.
4. Fully Connected Layers
After several rounds of convolution and pooling, the CNN will typically have a set of feature maps that highlight various features of the input image. These feature maps are then passed to fully connected layers, also known as dense layers.
- Flattening: Before feeding the feature maps into fully connected layers, they must be flattened into a one-dimensional vector. Flattening transforms the two-dimensional feature maps into a single long vector of values.
- Fully Connected Layers: These layers are similar to the layers found in traditional feed-forward neural networks. Each neuron in a fully connected layer is connected to every neuron in the previous layer, enabling the network to make decisions based on the features extracted by the convolutional and pooling layers.
- Example: In the case of image classification, once the network has identified various features of the image (edges, textures, shapes), the fully connected layers combine these features to classify the image into a category (e.g., "dog" or "cat").
5. Output Layer (Softmax or Sigmoid)
The final layer in a CNN is typically the output layer, where the network makes its final prediction. The output layer is usually a softmax layer (for multi-class classification) or a sigmoid layer (for binary classification).
- Softmax: In multi-class classification problems (e.g., classifying images into multiple categories), the softmax function outputs a probability distribution across all classes. Each output neuron represents the probability of the input image belonging to a particular class, and the class with the highest probability is chosen as the predicted class.
P(yi)=ezi∑jezjP(y_i) = \frac{e^{z_i}}{\sum_j e^{z_j}}
where ziz_i represents the raw score (logit) of class ii, and the sum in the denominator ensures that all probabilities add up to 1. - Sigmoid: For binary classification problems (e.g., distinguishing between two classes), a sigmoid function is used in the output layer, which outputs a probability between 0 and 1, indicating the likelihood of belonging to one of the two classes.
- Example: In a CNN for dog vs. cat classification, the output layer would output probabilities like 0.8 (dog) and 0.2 (cat). If the threshold for classification is set at 0.5, the image would be classified as a dog.
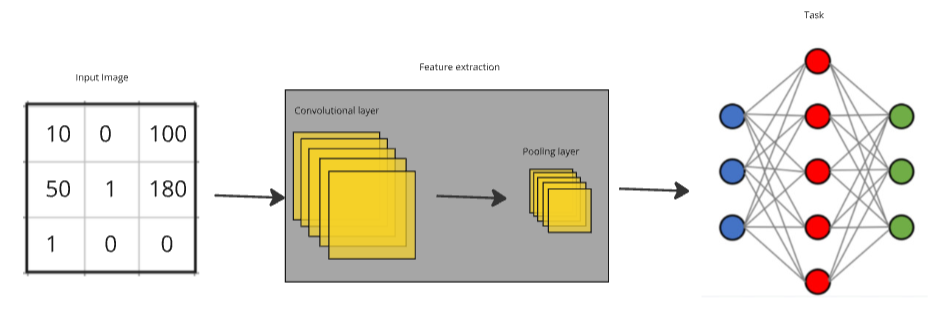
These key components work together to allow the network to automatically learn the most relevant features from raw image data and use those features for classification or detection tasks. Convolutional layers capture low-level features like edges and textures, pooling layers reduce the complexity, and fully connected layers interpret those features to make decisions.
By building these layers in a deep architecture, deep convolutional neural networks (DCNNs) can tackle complex tasks like image classification, facial recognition, and even self-driving car navigation, making them a cornerstone of modern computer vision.
Building Your First Convolutional Neural Network
Now that we understand the components of a CNN, let's get hands-on and build one. We will use Python and TensorFlow to implement a simple CNN and train it on the MNIST dataset, which contains 28x28 grayscale images of handwritten digits (0-9).
Step 1: Install Required Libraries
Before we start coding, ensure you have the necessary libraries installed. We’ll be using TensorFlow for building and training the model, NumPy for numerical operations, and Matplotlib for visualizations.
pip install tensorflow numpy matplotlib
Step 2: Import the Libraries
Now that the libraries are installed, we can import them into our Python script.
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
Step 3: Load and Prepare the Dataset
For this guide, we will use the MNIST dataset, a classic dataset for image classification that contains 60,000 training images and 10,000 testing images of handwritten digits. We can load this dataset easily with TensorFlow.
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# Normalize the images to values between 0 and 1
x_train, x_test = x_train / 255.0, x_test / 255.0
# Reshape the images to be 28x28x1 for grayscale
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
In this step, we load the training and testing images, normalize their pixel values to a range between 0 and 1, and reshape the images to ensure they are in the correct format (28x28x1).
Step 4: Build the CNN Model
Now we will define our deep convolutional neural network. The model will consist of three types of layers:
- Convolutional Layers to detect basic features like edges and textures.
- Max Pooling Layers to reduce the spatial dimensions.
- Fully Connected Layers to classify the image.
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'), layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'), layers.Flatten(), layers.Dense(64, activation='relu'), layers.Dense(10, activation='softmax')])
In this architecture:
- The first convolutional layer detects simple features (like edges), followed by max pooling to reduce the size.
- The second convolutional layer captures more complex features.
- The third convolutional layer adds further depth to the feature extraction.
- Finally, the fully connected layer and softmax output layer classify the image into one of 10 digits (0-9).
Step 5: Compile the Model
Once the model is defined, we need to compile it by specifying the optimizer, loss function, and evaluation metrics. For image classification, we use categorical cross-entropy as the loss function and accuracy as the metric.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
The Adam optimizer is an adaptive learning rate optimization algorithm that works well for a variety of tasks. We’ll use sparse categorical cross-entropy because our labels are integer values (0-9), and we want to classify them directly without one-hot encoding.
Step 6: Train the Model
Now, we can start training the model using the training data. This will train the convolutional networks and learn the features in the images.
history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
We will train the model for 5 epochs, which means the model will iterate over the entire training dataset five times. The validation data will be used to check the model's performance after each epoch.
Step 7: Evaluate the Model
After training, we will evaluate how well our model performs on the test data.
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f'Test accuracy: {test_acc}')
This will print the model's accuracy on the test set, giving us an indication of how well it generalizes to unseen data.
Step 8: Visualize the Results
Finally, we can visualize the training and validation accuracy over the epochs to see how the model improved during training.
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
This will plot a graph showing how the model's accuracy improved over time, as well as the validation accuracy, which gives an idea of the model's performance on unseen data.
Conclusion
Congratulations! You've successfully built and trained your first convolutional neural network for image classification. Understanding what are convolutional neural networks and how they work is fundamental for anyone starting in the field of deep learning. CNNs are powerful tools, especially for tasks involving image data, and they form the basis of many state-of-the-art models in computer vision.
With this knowledge, you can experiment with deeper and more complex models, try different datasets, and explore other applications of CNNs like object detection, facial recognition, and more. Keep building and experimenting—there's so much to discover in the world of deep learning!










.png)
