


What is Feature Scaling in Machine Learning?
Feature scaling is a crucial preprocessing step in machine learning that transforms data so that its features are on a similar scale. Since many machine learning algorithms rely on numerical distances or gradient-based optimization, scaling ensures the model performs efficiently and accurately.
When is Feature Scaling Necessary?
Feature scaling is especially important for:
- Algorithms that rely on distance calculations (e.g., KNN, K-Means Clustering)
- Gradient-based optimizers (e.g., Logistic Regression, Neural Networks)
- Tree-based models like Decision Trees and Random Forests are generally unaffected by feature scaling.
Why is Feature Scaling Important?
Feature scaling plays a critical role in ensuring that a machine learning model performs accurately and efficiently. When a dataset contains numerical features with significantly different ranges, the model can become biased toward higher magnitude features, resulting in poor predictions.
Let's understand the importance of feature scaling with an example:
Example: Height and Weight in a Dataset
Suppose you have a dataset with two features:
- Height: Ranges from 150 cm to 200 cm
- Weight: Ranges from 40 kg to 150 kg
Without feature scaling, a machine learning algorithm may assign more importance to Weight because its numerical range (40-150) is significantly higher than Height (150-200). This disproportionate influence can lead to incorrect predictions or slow convergence during model training.
Impact on Different Types of Algorithms
Feature scaling affects different algorithms in different ways. Here's how:
Distance-Based Algorithms (KNN, K-Means, SVM):
- These models calculate distance between data points using Euclidean distance.
- If one feature has a larger range, it will dominate the distance calculation, misleading the model.
- Feature scaling ensures equal contribution from all features.
Gradient-Based Algorithms (Linear Regression, Logistic Regression, Neural Networks):
- These algorithms use gradient descent to minimize the cost function.
- If features have different scales, the gradient may oscillate, slowing down convergence or causing the algorithm to miss the optimal solution.
- Scaling speeds up convergence and improves model performance.
You can checkout in detail about linear regression here
Tree-Based Algorithms (Decision Tree, Random Forest, XGBoost):
- These models are not sensitive to feature scaling.
- Feature importance is based on splits, not distances or gradients.
- Scaling is not necessary for these models.
To know more about Random forest, check here.
A Real-World Analogy
Imagine you are driving a car from City A to City B with two signboards:
- Signboard 1: Distance to City B → 5 km
- Signboard 2: Fuel Price → ₹100 per liter
If you only focus on the numerical value, you'd think the fuel price (100) is more significant than the distance (5). However, logically, the distance is more critical for travel planning. This is exactly what happens in machine learning without feature scaling — the model is misled by large numerical values.
- Feature scaling ensures that no particular feature dominates the learning process.
- It helps models converge faster and improves prediction accuracy.
- Always scale features when using distance-based or gradient-based algorithms.

Types of Feature Scaling Techniques
Feature scaling in machine learning can be performed using various techniques, depending on the dataset and the algorithm being used. The most commonly used methods are:
- Min-Max Scaling (Feature Normalization)
- Standardization (Z-Score Normalization)
- Robust Scaling (Using Median and IQR)
- Log Transformation (For Skewed Data)
Let's explore each technique in detail with formulas, use cases, and advantages.
1. Min-Max Scaling (Feature Normalization)
Min-Max Scaling, also known as feature normalization, transforms the data to a fixed range, typically [0, 1]. This ensures that all features contribute equally to the model without biasing higher magnitude features.
Formula:

When to Use Min-Max Scaling?
- When you want your features to be in a fixed range (e.g., [0,1] or [-1,1])
- Ideal for distance-based algorithms like KNN, K-Means, and SVM.
- Suitable for algorithms that use gradient descent like Logistic Regression, Neural Networks, and Deep Learning models.
Example:

Advantages:
- Easy to implement.
- Keeps the data in a fixed range without altering distribution.
Disadvantages:
- Highly sensitive to outliers.
- If the maximum or minimum value changes during testing, the scaling may become inaccurate.
2. Standardization (Z-Score Normalization)
Standardization transforms data so that it has zero mean (0) and unit variance (1). This technique is often preferred when the dataset has features with varying scales and the data may contain outliers.
Formula:
When to Use Standardization?
- Suitable for gradient-based algorithms like Logistic Regression, Linear Regression, SVM, and Neural Networks.
- Works well when features have very different scales.
- Preferred when data contains extreme values (outliers).
Example:

Standardization in Action: Centering Data for Stable Model PerformanceAdvantages:
- Handles outliers better than Min-Max Scaling.
- Keeps the data centered around zero with equal variance.
Disadvantages:
- Does not scale the data to a fixed range like [0,1].
- May not perform well if the data distribution is highly skewed.
3. Robust Scaling (Using Median and IQR)
Robust Scaling is designed to handle outliers by using the median (50th percentile) and interquartile range (IQR) instead of the mean and standard deviation.
Formula:

When to Use Robust Scaling?
- If your dataset contains extreme outliers.
- Recommended for KNN, SVM, Logistic Regression, and Neural Networks when outliers exist.
Example:

Advantages:
- Resistant to outliers.
- Ensures robust scaling without being affected by extreme values.
Disadvantages:
- May not work well with small datasets.
- Scaling still depends on the distribution of data.
4. Log Transformation (For Skewed Data)
Log transformation is commonly used when your data contains skewed distributions (i.e., when most data points are small, but few points are extremely large). This method reduces the effect of large values, making the distribution more normal.
Formula:

When to Use Log Transformation?
- When your data contains a large number of outliers.
- When you observe a right-skewed distribution (e.g., income, house price, transaction amounts).
- Commonly used in Linear Regression and Neural Networks.
Example:

Advantages:
- Handles skewed data effectively.
- Reduces the effect of large outliers.
Disadvantages:
- Only works for positive data values.
- Difficult to interpret the transformed data.
Choosing the Right Feature Scaling Method

Now that you know the different types of feature scaling techniques, the next important question is:
Which feature scaling method should you use for your machine learning model?
The answer depends on three major factors:
- The type of machine learning algorithm you're using.
- The distribution of your data (with or without outliers).
- The nature of your data (continuous, categorical, skewed).
Let's break this down for better understanding.
1. Choosing Based on Algorithm Type
Different machine learning algorithms have different sensitivities to feature scaling. Here's how you can decide:

- Distance-Based Algorithms like K-Nearest Neighbors (KNN), Support Vector Machines (SVM), and K-Means Clustering heavily rely on distance measurements. If features have vastly different scales, the algorithm will give higher importance to larger magnitude features. Hence, scaling is a must.
- Gradient-Based Algorithms like Linear Regression, Logistic Regression, and Neural Networks rely on gradient descent to minimize the loss function. Scaling helps the gradient converge faster.
- Tree-Based Algorithms like Decision Tree, Random Forest, XGBoost do not rely on distance or gradient descent. Hence, scaling is not required.
2. Choosing Based on Data Distribution
The nature of your dataset also influences the choice of scaling technique:

3. Choosing Based on Business Context
Sometimes, your choice of scaling may depend on the business use case or interpretability:

4. Quick Thumb Rule for Scaling Choice
If you're still confused, here’s a simple rule of thumb:

Also Read: End-to-End Guide to K-Means Clustering in Python: From Preprocessing to Visualization
Should You Scale Before or After Splitting Data?
- Always split your dataset (train-test split) first before applying feature scaling.
- Fit the scaler only on the training data and transform both training and testing data.
- This prevents data leakage.
Example:


Feature Scaling in Practice: Python Implementation
Now that you understand the theory behind feature scaling, let's implement the different scaling techniques using Python's Scikit-learn library. I'll cover the following:
- Min-Max Scaling (Feature Normalization)
- Standardization (Z-Score Normalization)
- Robust Scaling (for Outliers)
- Log Transformation (for Skewed Data)
I'll use a simple dataset with Height, Weight, and Income to demonstrate each technique.
Step 1: Import Libraries and Sample Data

Output:

Step 2: Apply Min-Max Scaling (Feature Normalization)
Min-Max Scaling transforms data to a fixed range, typically [0,1]. This is helpful for distance-based algorithms.

Output:
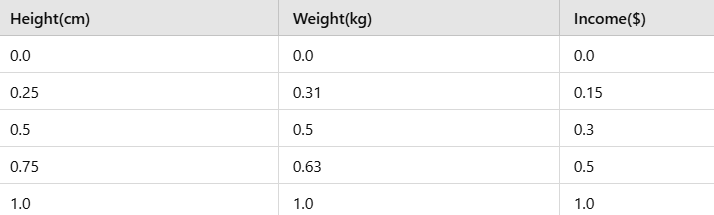
All features are now scaled between 0 and 1.
Step 3: Apply Standardization (Z-Score Normalization)
Standardization transforms data to have zero mean and unit variance (1). It's ideal for gradient-based algorithms like Logistic Regression, Neural Networks, etc.

Output (approx.):

The data is centered around 0 and has unit variance.
Step 4: Apply Robust Scaling (for Outliers)
Robust scaling is useful when data contains outliers. It uses median and IQR to scale data, making it resistant to outliers.

Output (approx.):

The scaling is less affected by extreme income ($150,000) outlier.
Step 5: Apply Log Transformation (for Skewed Data)
If the income column is heavily right-skewed, log transformation can make it more normally distributed.

Log transformation compresses large income values, reducing skewness.
Step 6: Compare the Results
Here's a quick comparison of scaling methods:

Step 7: Avoid Data Leakage (Important!)
Always apply scaling on the training set only, and use the same transformation on the test set.
Correct Way:

This prevents data leakage and improves model generalization.
Also Read: Principal Component Analysis (PCA): Simplifying Data Without Losing Insights
Common Mistakes and Best Practices in Feature Scaling
Even though feature scaling seems straightforward, many beginners and even experienced data scientists often make critical mistakes during the scaling process. These mistakes can lead to data leakage, inaccurate predictions, or poor model performance. In this section, I'll cover:
Scaling Before Train-Test Split (Data Leakage)
Many beginners apply feature scaling before splitting the data into training and testing sets. This is a huge mistake because:
- The test data leaks into the training data through the scaling step.
- The model gets "informed" about the test data distribution, leading to overfitting.
Always split your data first and then fit the scaler only on the training data. Use the same fitted scaler to transform the test data.
- The test data remains unseen during training.
- Prevents data leakage and overfitting.
Scaling Categorical Data
If your dataset has categorical features like Gender, City, Marital Status, etc., you should never scale categorical variables. However, many beginners apply scaling to categorical data, which doesn't make sense.
- Scaling categorical variables has no logical meaning.
- It may confuse the model.
- One-hot encode or label encode categorical features instead of scaling them.
- Only scale numerical features.
- Ensures categorical data remains meaningful.
- Avoids misleading feature importance.
Applying Different Scaling on Train and Test Data
Some people fit the scaler separately on training and test data, thinking it would give better accuracy. This is a big mistake.
- The training and test data now have different scales.
- The model will fail during testing.
Always fit the scaler only once (on training data) and use the same scaler to transform the test data.
-Keeps both training and testing data on the same scale.
- Prevents test data leakage.
Ignoring Feature Scaling for Gradient-Based Algorithms
Some people forget to scale data when using gradient-based algorithms like:
- Logistic Regression
- Linear Regression
- Neural Networks
This can significantly slow down the learning process or even cause the model to fail convergence.
- Gradient descent struggles with large numeric ranges.
- The model may get stuck in local minima.
Always apply Standardization or Min-Max Scaling when using gradient-based algorithms.
- Ensures faster convergence of gradient descent.
- Improves model performance.
Using Min-Max Scaling with Outliers
If your data contains outliers, applying Min-Max Scaling is a bad idea because:
- Outliers will pull the minimum and maximum range, distorting the entire scale.
- The small values (1, 2, 3) will become nearly zero.
- The large outlier (1000000) will dominate the scale.
If your data has outliers, always use Robust Scaling or Log Transformation.
- Ignores outliers by using the Median and IQR.
- Provides a stable scale.
How to Check If Scaling Worked Perfectly?
After scaling your data, always check:

Expected Results:
- For Standardization, the mean should be 0 and standard deviation 1.
- For Min-Max Scaling, values should be between [0,1].
- For Robust Scaling, the median should be approximately 0.
Conclusion
Feature scaling is a critical step in the machine learning pipeline that ensures all features contribute equally to model performance, especially when dealing with distance-based or gradient-based algorithms. By scaling your data, you can prevent certain features from dominating the model, speed up gradient descent convergence, and improve overall prediction accuracy.
However, it's equally important to choose the right scaling method based on the nature of your data and avoid common mistakes like data leakage, scaling categorical data, or applying different scalers on train and test data.
Always remember —
- Min-Max Scaling is ideal for small-range data,
- Standardization works best for normally distributed data,
- Robust Scaling handles outliers, and
- Log Transformation reduces skewness.
Mastering feature scaling will give you a significant edge in building high-performing machine learning models. So next time you build a model, don’t forget to scale smartly, not blindly!



.jpeg)









.avif)

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra.